-
My Projects
Pick any project to read and learn more about my experience as a developer, team leader, analyst, and so much more!
+
-
1
Haptic Feedback Device Tester
As a Software Engineering Intern at BCS Automotive Interface Solutions, I developed a comprehensive Haptic Feedback Device Testing GUI using Python and Tkinter as part of a larger project focused on refining and personalizing tactile responses in automotive control systems. The primary goal of the tool was to provide an intuitive interface for engineers and product teams to design, visualize, and fine-tune vibration waveforms tailored to different types of haptic actuators, such as ERM, LRA, piezoelectric, and electromagnetic devices.
The application supports real-time waveform customization using adjustable sliders and graphical plotting through Matplotlib, allowing users to generate and manipulate response curves, save them to CSV files, and load preset waveforms for reuse or calibration. To support device communication, I integrated serial port connectivity, enabling live interaction between the software and the physical haptic hardware. The UI dynamically enables or disables actuator tabs based on whether a COM port is connected, and different actuator modes (basic, advanced, and audio-to-vibe) are available for each actuator type. The system includes a modular structure with tabs for each actuator, waveform graphing, register-level configuration for fine-tuning low-level device parameters, and support for importing/exporting test patterns. As part of a customer-focused development cycle, the GUI provided a flexible and testable platform for evaluating how specific vibration profiles feel, which helped ensure final haptic implementations aligned with client expectations. This tool directly contributed to our ability to iterate quickly and deliver refined tactile experiences in next-generation automotive HMIs.
The backend of this system was initially enacted in Arduino then later programmed into C++ and preprogrammed into the embedded controller chip housed within the test device. This backend established the control logic necessary for interpreting incoming serial commands from the Python GUI and translating them into actuator-level responses. Through serial communication, we were able to manipulate register values, activate specific haptic effects, and experiment with waveform-driven behaviors in real time. This C++ firmware layer served as the critical bridge between software and hardware, allowing us to program, test, and iterate on various vibration patterns quickly. This flexible architecture enabled us to adapt the system to different actuator types and client use cases, making it a powerful platform for tailored haptic feedback development.
+
-
2
Self – Trained AI Chatbot
This project was built as part of NextGen Advanced AI, a project I co-founded with fellow Loyola University Chicago students.
For this project, I fine-tuned the DeepSeek-R1-Distill-Qwen-1.5B model from Hugging Face using LoRA (Low-Rank Adaptation), which allowed me to update the model with minimal compute by injecting lightweight, trainable adapters into a frozen base model. Since I work on a Mac, I optimized everything to run on the MPS (Metal Performance Shaders) backend, though the project can be adapted for Windows or Linux with appropriate CUDA support. I created a training script that loads prompt-completion pairs from a .json file, formats them for instruction tuning, and saves the LoRA adapter for later use.
For deployment, we built a Flask API that serves the fine-tuned model via a /generate endpoint. This lets users send prompts and receive real-time streamed responses. Initially, my team and I used Ollama for local model hosting, but I later shifted to using torch and transformers directly to make the app more self-contained. I also helped redesign the frontend using React and Vite, allowing for a sleek chat interface with live updates. We used Axios for frontend-backend communication and integrated Docker to make the environment consistent across machines.
I focused the fine-tuning on philosophical reasoning, curating questions that challenge the model to provide clear, deep, and concise responses. To test it, I wrote a script that sends prompts from a .txt file via curl and logs the answers for review. I manually evaluated the responses to ensure the model was improving over the base version, especially in clarity and topical relevance. Although I didn’t test it with mathematical or highly difficult questions, the model performed well even on general knowledge.
Link: https://github.com/kneeble/PhilosophicalDeepseekLLM
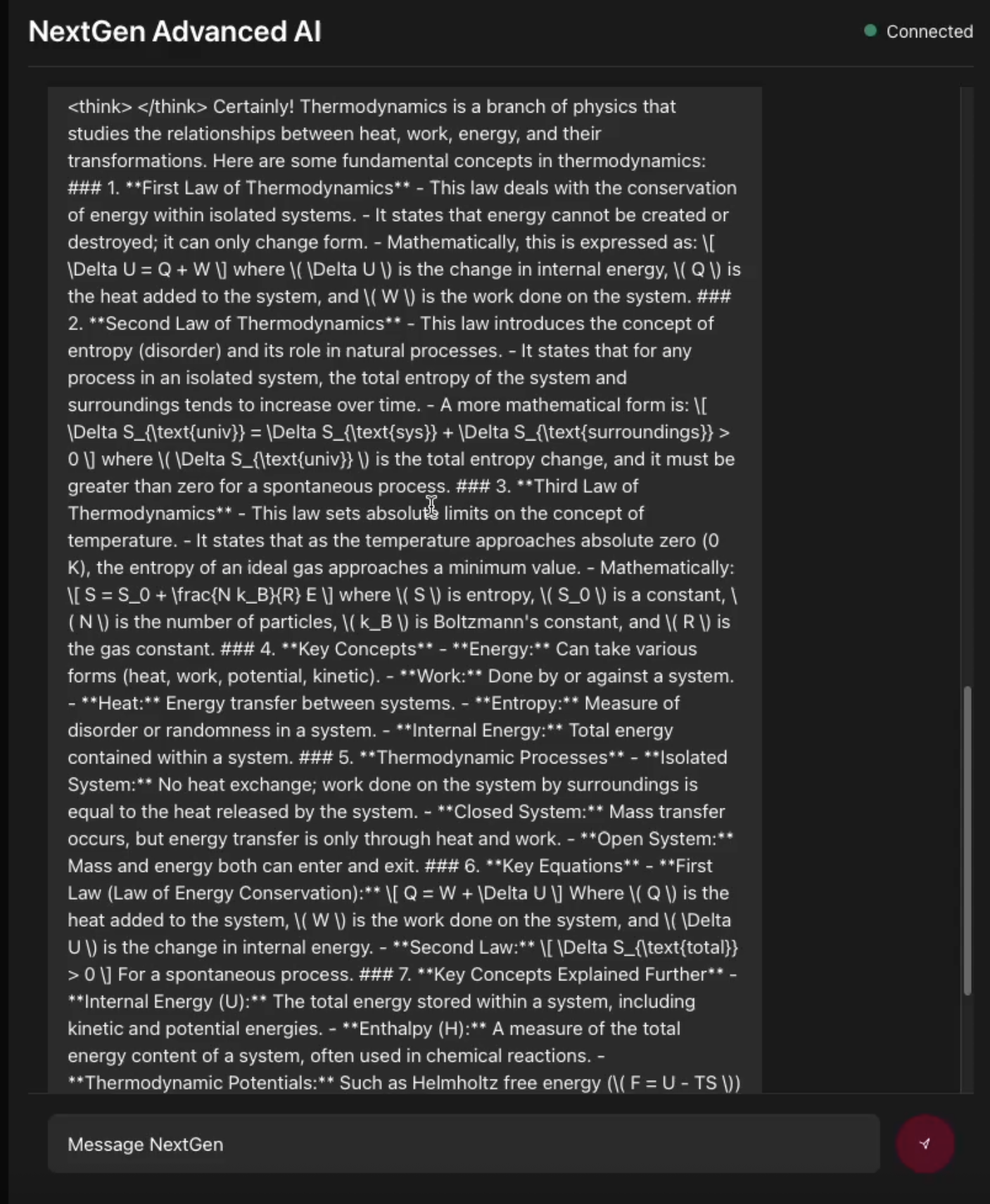
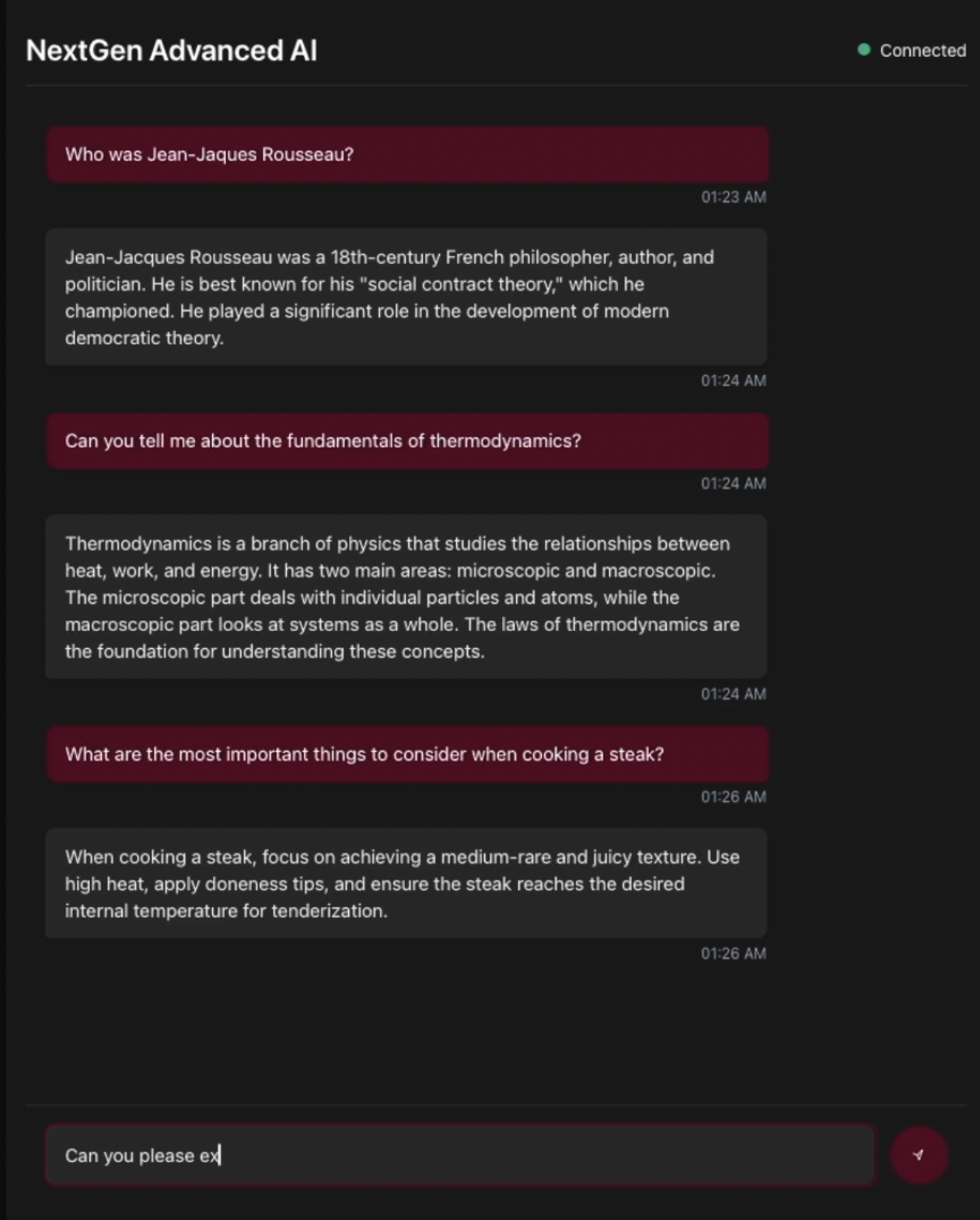
Optimization of processing times & simplification and formatting of answer after training & fine-tuning. +
-
3
Premier League Data and Prediction Platform
A significant academic project I led at Loyola University Chicago was Futstat, a full stack Premier League analytics platform developed for COMP 330 – Software Engineering. Acting as Project Lead, I oversaw the entire development lifecycle, coordinating a team of five developers, establishing project architecture, and managing version control to ensure alignment across frontend, backend, and data science components. The platform delivers live match scores, intelligent predictions, and comprehensive historical statistics through a modern dashboard built with React.js, Node.js with Express, and PostgreSQL, integrating real time football data feeds from external APIs.
My technical contributions centered on backend development, database architecture, and the machine learning prediction system. I configured the PostgreSQL database infrastructure, architected the schema to support complex queries across normalized tables, and established secure, efficient connections between the Express API and database layer. I developed Python ETL pipelines for automated data ingestion, populating the system with 25 years of historical match data, team statistics, and player performance metrics.
A primary focus was designing and implementing the machine learning prediction system from the ground up. I developed supervised learning models using scikit-learn, training on historical data through extensive feature engineering that incorporated rolling team form metrics, head to head performance, home/away indicators, rest days, and weighted seasonal trajectories. I experimented with multiple algorithms including logistic regression, random forests, and gradient boosting (XGBoost), implementing cross validation with temporal splits to prevent data leakage and grid search for hyperparameter tuning. The final production model outputs class probabilities for nuanced match outcome predictions. I serialized the trained models using pickle and integrated them into the Express backend through Python child processes, enabling real time inference via RESTful API endpoints.
On the frontend, I designed the predictions tab to visualize model outputs effectively, displaying upcoming fixtures with probability distributions, confidence intervals, and historical accuracy statistics. I also integrated interactive elements allowing users to explore feature importance, making the model’s decision making process transparent and interpretable. Throughout development, I established coding standards, conducted code reviews, managed pull requests, and maintained comprehensive technical documentation. This project demonstrated my full stack and machine learning engineering capabilities, encompassing data pipeline development, feature engineering, model training, API integration, database optimization, and technical leadership in a collaborative software environment.
Link: https://eplanalyticsplatform.vercel.app/
Github: https://github.com/osanchezhuezca/Premier-League-Analytics-Platform
+
-
4
Secondary Major Reccomender
For this project I acted as the main project lead and primary architect to build a web based Major Recommender System in collaboration with Dr. Catherine Putonti at Loyola University Chicago. This was part of a consulting project that focused mainly on software development, meaning that this project also integrated into the current Loyola University tech stack.
My contributions focused on delivering a functional solution from concept to prototype. This involved designing the overall project structure and core algorithm to intelligently match student coursework with scraped major requirements, forming the foundation for generating personalized academic recommendations. I also developed the complete data pipeline and web application, including scripts for gathering course data, the central recommendation logic, and the Flask based user interface to ensure a seamless user experience. Beyond development, I led the team and drove technical communication to coordinate tasks, align the project with the advisor’s vision, and successfully deliver a prototype that demonstrates how data can help students discover alternative graduation paths.
+
-
5
Organizational Tool Database & Website
Another project I assisted with at BCS Automotive Interface Solutions during my time as an intern was a tool organizer and database website using PHP and MySQL, designed to manage internal workflows, member profiles, and content dynamically. The site was initially developed and hosted locally using XAMPP, which allowed for rapid prototyping and database integration in a self-contained environment. I created a responsive frontend with HTML, CSS, and JavaScript, while the backend logic handled user authentication, session management, and data-driven interactions—such as event registrations, contact forms, and content submission portals. MySQL was used to manage structured data, including user accounts, announcements, and document storage.
The platform was built with modularity and scalability in mind, with reusable PHP components for headers, footers, and navigation menus, and secure database interaction via parameterized SQL queries to prevent injection vulnerabilities. During development, XAMPP enabled efficient testing of features like email notifications, file uploads, and CRUD operations without relying on an external server. Future plans for deployment included migration to a remote LAMP server or integration into a cloud-based infrastructure. This project laid the groundwork for a functional, secure, and maintainable system tailored for organizational needs.
+
-
6
Multiple Linear Regression Modeling & Analysis For Football Data
In this project, I conducted a multiple regression analysis to explore the statistical factors that best predict a Premier League team’s final league ranking during the 2023–2024 season. After importing and preprocessing a dataset containing 75 performance metrics—including expected goals (xG), possession percentage, and passing statistics—I applied a structured model selection process. I first removed variables such as total points and points per match due to multicollinearity with team rank, a key assumption that can distort regression estimates if violated. Using SAS, I identified a candidate model based on statistical fit and refined it using Variance Inflation Factor (VIF) analysis to assess multicollinearity, followed by manual backward elimination based on variable significance.
The final regression equation was:
Rank = 45.36442 – 0.26055(x₁) – 0.00627(x₂) – 0.04556(x₃)
where:- x₁ = Expected Assisted Goals
- x₂ = Passes into Final Third
- x₃ = Times Dispossessed
This model satisfied standard linear regression assumptions, including linearity, independence, and approximately normal residuals. All predicted team ranks fell within a reasonable range of actual values, with no residual exceeding three times the Root Mean Squared Error (RMSE), indicating no high-leverage outliers or undue influence from any single observation. The model’s structure also reinforced the expected importance of creative metrics like expected assists and forward passes—but revealed an unexpected insight: a higher dispossession rate correlated with better league rankings, challenging traditional interpretations.
Rather than indicating weakness, this trend likely reflects aggressive playstyles employed by elite teams, such as Liverpool’s high-pressing “gegenpressing” system, which involves rapidly regaining possession to create scoring opportunities. Supporting research from Serie A and tactical studies confirms that teams with high intensity and offensive pressure may naturally incur more dispossessions as a byproduct of dominance, not disorganization.
+
-
7
Football Match Outcome Calculator
For another project, I developed a Soccer Match and 1v1 Predictor—a Python-based application that combines real-world data analysis, machine learning modeling, and a graphical user interface (GUI) to simulate and predict outcomes for both team matchups and individual 1v1 player scenarios. Built using libraries such as pandas, numpy, scikit-learn, and tkinter, the program integrates statistical modeling with user interactivity to make soccer-based predictions both informative and engaging.
The application is structured around three main components. First, it performs data preprocessing by loading team and player data from Excel sheets, encoding categorical variables, and cleaning player names to ensure smooth interaction within the interface. Next, it applies machine learning techniques, primarily logistic regression and Monte Carlo simulation, to estimate win/loss probabilities for team matchups and individual player duels. Team predictions consider season-level statistics and venue data, while individual predictions compute feature differences between players for success estimation.
The GUI, designed using tkinter, features two tabs: a Team Matchup Predictor and a 1-on-1 Player Predictor. Users can dynamically select players or teams, view win probabilities, success rates, common formations, and additional tactical information in a polished, responsive layout. Real-time player search and automatic team mapping enhance usability.
Challenges in the project primarily stemmed from data quality issues, particularly dealing with NaN values and inconsistent formatting when importing real-world soccer statistics. Tuning the regression models and ensuring proper data alignment required significant debugging and research.
+
-
8
Other Experience & Certificates
I have a strong academic foundation and a diverse skill set in data analytics, software development, and education. I amPursuing a Bachelor of Science in Software Engineering and Data Science at Loyola University Chicago, with a GPA of 3.1 and two semesters on the Dean’s List, all the while working on most of the projects listed above.
I completed the Google Data Analytics Certificate in one week, gaining hands-on experience in data cleaning, analysis, and visualization using tools like R, SQL, and Tableau for real-world business applications.
I also earned the Football Data Analytics certification at Universidad Europea de Madrid Escuela Universitaria Real Madrid, where I applied machine learning and visualization tools such as MySQL, Pentaho, R, Power BI, and Tableau to develop and interpret key performance indicators in sports contexts.
I graduated from Novi High School with a 4.0 weighted GPA, a 1400 SAT score, and earned distinctions including the President’s Award for Educational Excellence, an AP Capstone Diploma, and College Board Hispanic National Recognition. My tutoring and mentoring experience in Chicago spans both high school and middle school students, with a focus on English and advanced mathematics.
Fluent in English and Spanish and conversational in French and Italian, I also bring a broad technical skill set across Python, Java, JavaScript, Flask, Linux, C, C++, C#, R, MySQL, SAS, PHP, Tableau, Power BI, Pentaho, Web Scraping and more. My experience covers embedded systems, machine learning, full-stack development, and statistical modeling. I’ve also volunteered for two years as an acting coach and assistant director, developing strong leadership and communication skills alongside my technical expertise.
+
